Матрица корреляции
Матрица корреляции по всем признакам
Появляется в результате применения блока Матрица корреляции (подробнее см. в этом разделе). Таблица показывает коэффициенты корреляции между парами признаков, расположенными на осях.
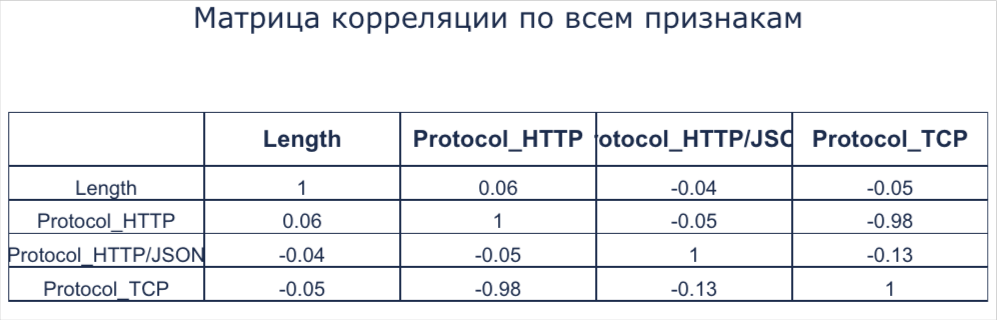
Таблица «Матрица корреляции»
Косинусное расстояние
Таблица с наблюдениями, наиболее схожими с входным вектором. Наибольший интерес представляют столбцы session_id и cos_sim.
- cos_sim – это сокращение от cos similarity, то есть “косинусная схожесть”. Чем меньше значение этой метрики, тем более похожи объекты. В таблице представлены топ-10 самых похожих объектов, относительно выбранного.
- session_id – уникальный номер объекта
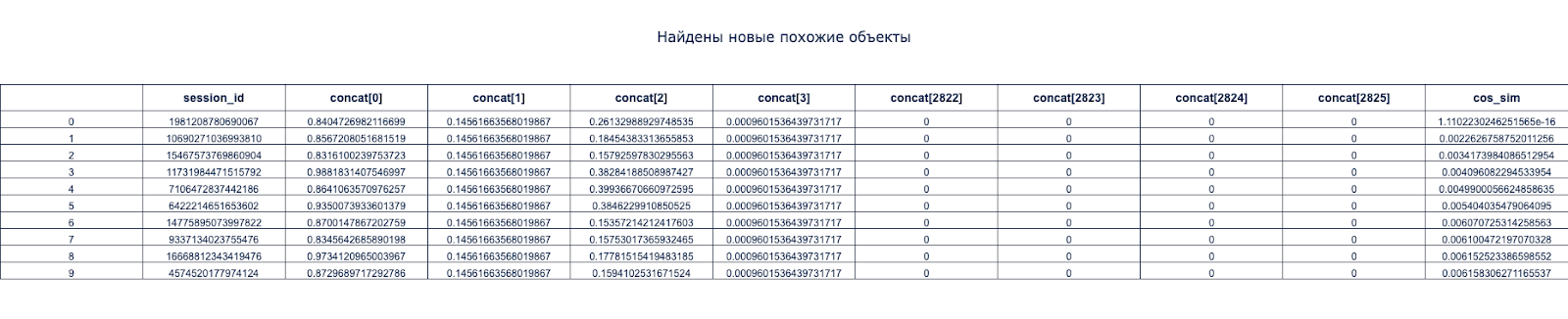
Таблица «Косинусное расстояние»
Тест Дики Фуллера на стационарность
Появляется в результате применения блока Тест Дики-Фуллера (подробнее см. в этом разделе). На таблице представлены показатели для исследуемых признаков, где:
- statistic – это промежуточная величина, которая используется для расчета p_value.
- p_value (значение вероятности) – это вероятность появления экстремального Наблюдения (Observation) при условии истинности Нулевой гипотезы;
- output – оценка стационарности временного ряда. True – означает, что ряд стационарен. False – нестационарен.
- text – интерпретация результата в текстовой форме.

Таблица «Тест Дики-Фуллера на стационарность»
Коэффициент асимметрии Skewness
Появляется в результате применения блока Коэффициент асимметрии Skewness (подробнее см. в этом разделе). На таблице представлены показатели для исследуемых признаков, где:
- mean – среднее значение признака.
- median – серединное значение набора чисел или число, которое находится в середине этого набора, если его упорядочить по возрастанию, то есть такое число, что половина из элементов набора не меньше него, а другая половина не больше.
- variance – дисперсия случайной величины или мера разброса значений случайной величины относительно её математического ожидания.
- statistic – промежуточная расчетная величина.
- output – оценка нормальности распределения признака. True – означает, что распределение нормально. False – отлично от нормального.
- text – интерпретация результата в текстовой форме.
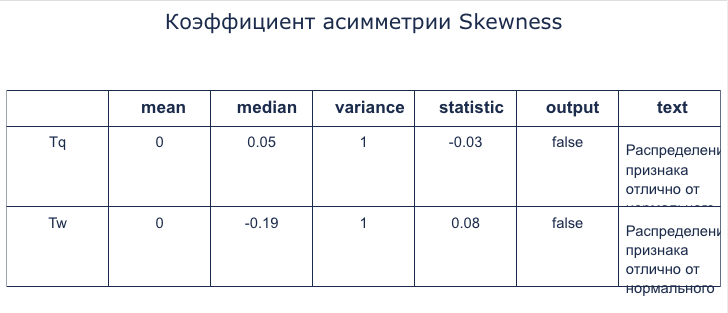
Таблица «Коэффициент асимметрии Skewness»
Валидация модели
Валидация на тестовой выборке.
Появляется в результате применения блока Валидация модели. Представляет собой расчет выбранной метрики для каждого признака.
Например если была выбрана MAE, то в таблицу будет выведено её значение. МАЕ – метрика, которая сообщает нам среднюю абсолютную разницу между прогнозируемыми значениями и фактическими значениями в наборе данных. Чем ниже MAE, тем лучше модель соответствует набору данных.

Таблица «Валидация на тестовой выборке»
Ошибка модели при прогнозировании классов:
Появляется в результате применения блока Валидация модели (Spark и классическая). В таблице отображается результат обработки тестового датасета, после обучения модели на обучающем датасете. Можно увидеть сколько ошибок допустила модель, а сколько классов были определены верно:
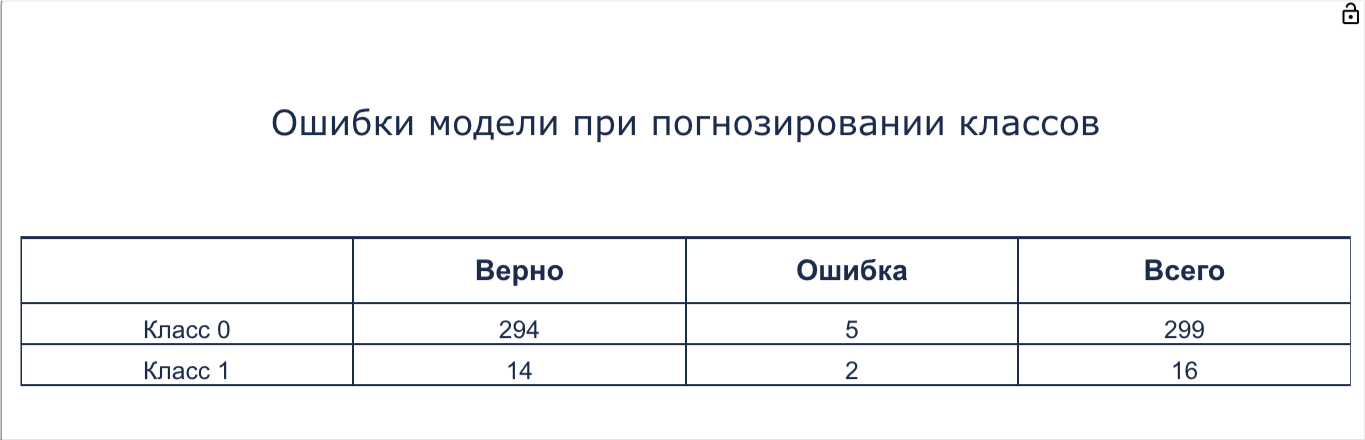
Таблица «Ошибки модели при прогнозировании классов»
Кластеризация
Количество объектов в каждом кластере
Появляется в результате применения блоков Кластеризация DBSCAN, Кластеризация K-Means, Кластеризация Spark DBSCAN, Метод локтя K-Means, Агломеративная иерархическая кластеризация и Изоляционный лес (подробнее см. в этом разделе).
В таблице представлены два столбца:
- label – это номер кластера
- volume – количество объектов в данном кластере.
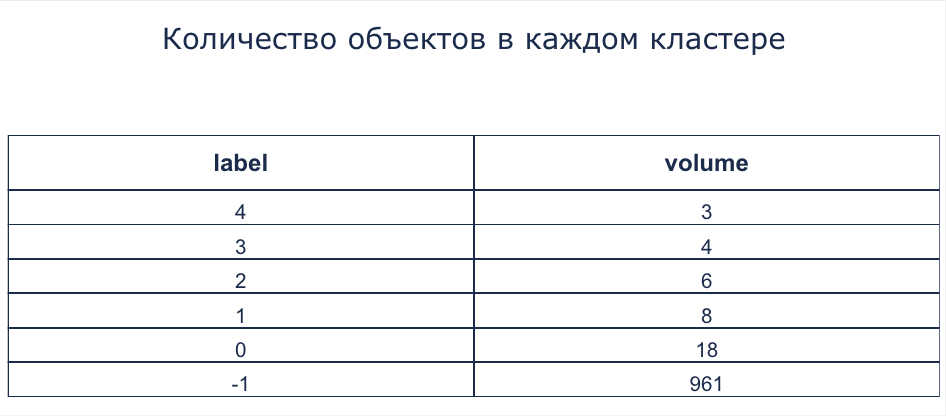
Таблица «Количество объектов в каждом кластере»
Центроиды
Появляется в результате применения блока Кластеризация K-Means (подробнее см. в этом разделе). В таблице представлены значения центроидов для каждого исследуемого признака и каждого кластера. Центроиды — центры тяжести кластеров. Каждый центроид — это вектор, элементы которого представляют собой средние значения соответствующих признаков, вычисленные по всем записям кластера.
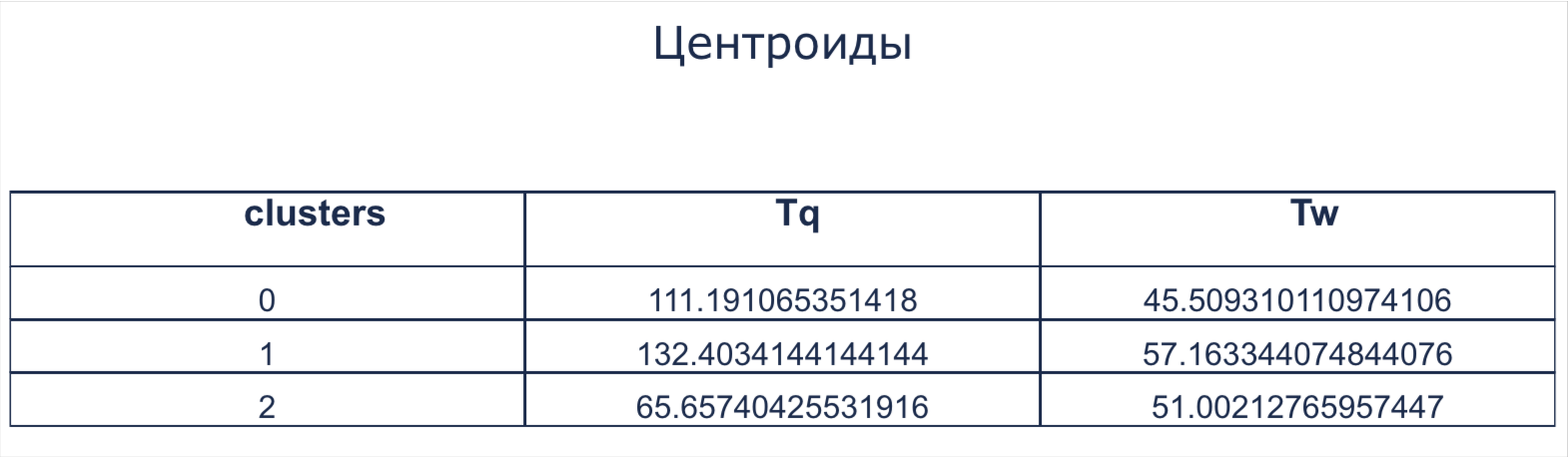
Таблица «Центроиды» K-Means
Предобработка данных
Отфильтрованные текстовые данные
Появляется в результате применения блока Фильтрация текстового шума (подобнее см. в этом разделе) и содержит в себе текст, прошедший процедуру фильтрации. На примере ниже функция применялась на датасете для классификации, поэтому также содержит столбец label обозначающий принадлежность к классу.

Лемматизированные текстовые данные
Появляется в результате применения блока Лемматизация текста (подобнее см. в этом разделе) и содержит в себе текст, прошедший процедуру лемматизации. На примере ниже функция применялась на датасете для классификации, поэтому также содержит столбец label обозначающий принадлежность к классу.

Классификация
История обучения
Появляется в результате применения блока Классификация изображений (подробнее см. в этом разделе) и содержит в себе информацию отражающую качество обучения модели. На графике представлена красная линия (Метрика Accuracy), отражающая точность классификации по мере повторения обучения (количество эпох). Синим цветом выделена Функция потерь – это показатель количетсво ошибок.
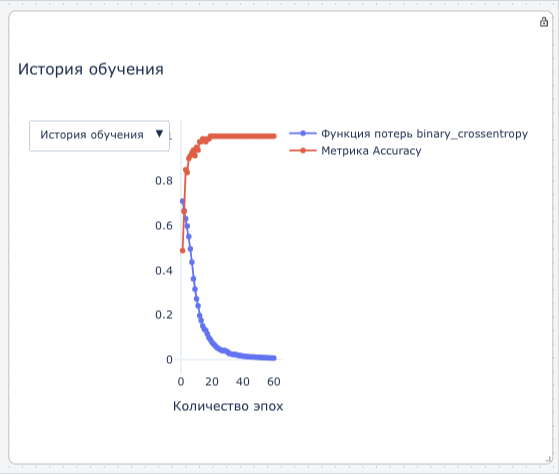
Графики истории обучения
Работа с текстом
Краткое содержание
Появляется в результате применения блока Автореферирование текста (подробнее см. в этом разделе) и содержит в себе текст, обработанный функцией автореферирования, выделяющей основную идею текста. На примере ниже функция применялась на датасете для классификации, поэтому также содержит столбец label обозначающий принадлежность к классу.

Графы
Число вершин и ребер графа
Появляется в результате применения блока Расчет параметров графа и содержит информацию по количеству вершин и ребер графа.

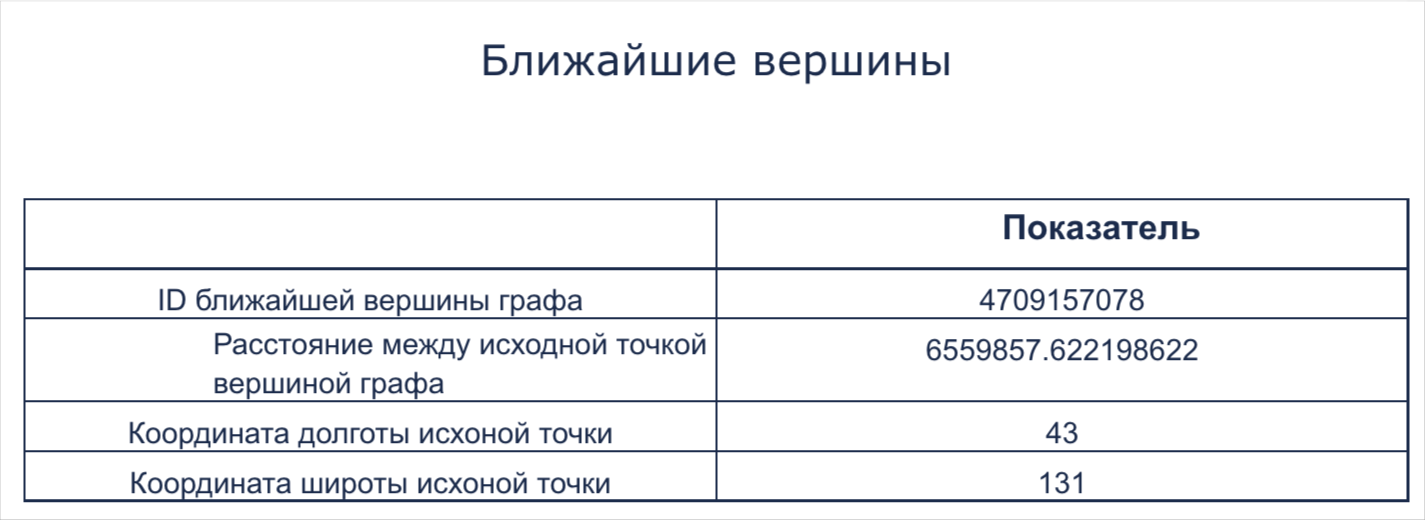
Ближайшие вершины
Появляется в результате применения блока Поиск ближайших вершин. Таблица включает в себя данные по ‘ID ближайшей вершины графа’, ‘Расстоянию между исходной точкой и вершиной графа’, ‘Координату долготы исходной точки’, ‘Координату широты исходной точки’ для каждой исходной пары координат. Каждый столбец Датасета и Таблицы является результатом вычислений для соответствующей пары координат, введенных пользователем.